
Introduction
Just one of the times you stumble upon an excellent dataset on Kaggle for a really interesting data mining problem - sarcasm detection in text and cannot resist to take a stab at it. I have looked for labelled datasets for this problem earlier but couldn’t find a reasonably clean corpus with sufficient instances.
But this json has a class-balanced dataset with ~27K news headlines labelled as sarcastic or non-sarcastic. Kaggle Link to Dataset
This weekend data mining endeavour has been a good exercise to make fun discoveries around what makes a news headline to be sarcastic. Some discoveries were quite specific to this dataset. For example - I was surprised when the words ‘Area’ and ‘Man’ appeared in my top 10 features to identify sarcasm in news headlines. But then I found out ‘Area Man’ is a sarcastic slang used as recurring joke on theonion.com
raw_df[tokenDF_Final.area == 1][['article_link','headline_feature','is_sarcastic']].head(3).reset_index(drop=True)
| article_link | headline_feature | is_sarcastic |
|---|---|---|
| https://local.theonion.com/area-woman-said-sorry-118-times-yesterday-1819576089 | area woman said ‘sorry’ 118 times yesterday | 1 |
| https://www.theonion.com/area-insurance-salesman-celebrates-14th-year-of-quoting-1819565058 | area insurance salesman celebrates 14th year of quoting fletch | 1 |
| https://local.theonion.com/is-area-man-going-to-finish-those-fries-1819565422 | is area man going to finish those fries? | 1 |
Whereas few discoveries are generalized and appear in sarcastic text everywhere and even corroborate with my personal experience. For example - ‘Clearly’ popped up in top 10 features. And if you think of it people do tend to use the word frequently in sarcastic remarks.
| article_link | headline_feature | is_sarcastic |
|---|---|---|
| https://www.theonion.com/jealous-gps-clearly-wants-man-to-back-over-wife-1819589581 | jealous gps clearly wants man to back over wife | 1 |
| https://politics.theonion.com/new-job-posting-on-craigslist-clearly-for-secretary-of-1819568699 | new job posting on craigslist clearly for secretary of the interior | 1 |
| https://www.theonion.com/elementary-schooler-clearly-just-learned-to-swear-1819566113 | elementary schooler clearly just learned to swear | 1 |
Cool… now, let’s get down to step-by-step going about the problem - Data Cleaning & Exploration, Feature Engineering & Model Training/Testing
Sample Data Exhibit
# Reading the JSON File
raw_df = pd.read_json('Sarcasm_Headlines_Dataset.json', lines=True)
# Extracting the Hostname from URL using regular expressions
raw_df['website_name'] = raw_df['article_link'].str.extract('(https://.*?[.]comhttp/'
'|https://.*?[.]com)', expand=True)
raw_df['website_name'] = raw_df['website_name'].str.replace('https://','').str.replace('/','').str.replace('comhttp','com')
raw_df = raw_df.drop(['article_link'], axis=1)
raw_df.head(3)
| headline | is_sarcastic | website_name |
|---|---|---|
| former versace store clerk sues over secret ‘black code’ for minority shoppers | 0 | www.huffingtonpost.com |
| the ‘roseanne’ revival catches up to our thorny political mood, for better and worse | 0 | www.huffingtonpost.com |
| mom starting to fear son’s web series closest thing she will have to grandchild | 1 | local.theonion.com |
The news articles from theonion are all sarcastic whereas the ones from huffingpost are all non-sarcastic. Since, the aim is to understand the linguistic features - vocabulary or semantics that help us identify sarcasm rather than building a 100% accurate model using just the website_name as a feature, we’ll not use this variable for modelling.
pd.pivot_table(raw_df, values=['is_sarcastic'], index=['website_name'], aggfunc=('sum','count'), fill_value=0)
| website_name | is_sarcastic - count | is_sarcastic - sum |
|---|---|---|
| entertainment.theonion.com | 1194 | 1194 |
| local.theonion.com | 2852 | 2852 |
| politics.theonion.com | 1767 | 1767 |
| sports.theonion.com | 100 | 100 |
| www.huffingtonpost.com | 14985 | 0 |
| www.theonion.com | 5811 | 5811 |
Data Cleaning
For NLP algorithms - Bag of Words or Doc2Vec, we’ll first need a clean set of tokens.
Note - Creating lists with List Comprehensions is more concise and significantly faster than defining functions with For Loops because it escapes calling append attribute of the list in each iteration. Hence, have resorted to LCs everywhere.
Ok, let’s first start by some standard data cleaning steps while working with text:
1. Tokenizing
# Split into Words
from nltk.tokenize import word_tokenize
raw_df['tokens'] = raw_df['headline_feature'].apply(nltk.word_tokenize)
2. Normalizing Case
# Convert to lower case
lower_case_tokens = lambda x : [w.lower() for w in x]
raw_df['tokens'] = raw_df['tokens'].apply(lower_case_tokens)
3. Removing Punctuation
# Filter Out Punctuation
import string
punctuation_dict = str.maketrans(dict.fromkeys(string.punctuation))
# This creates a dictionary mapping of every character from string.punctuation to None
punctuation_remover = lambda x : [w.translate(punctuation_dict) for w in x]
raw_df['tokens'] = raw_df['tokens'].apply(punctuation_remover)
4. Removing Non-alphabetic Tokens
# Remove remaining tokens that are not alphabetic
nonalphabet_remover = lambda x : [w for w in x if w.isalpha()]
raw_df['tokens'] = raw_df['tokens'].apply(nonalphabet_remover)
5. Filtering out Stop Words
# Filter out Stop Words
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
stopwords_remover = lambda x : [w for w in x if not w in stop_words]
raw_df['tokens'] = raw_df['tokens'].apply(stopwords_remover)
6. Stemming / Lemmatizing the Tokens
# Stem / Lemmatize the Words
from nltk.stem.wordnet import WordNetLemmatizer
lmtzr = WordNetLemmatizer()
word_lematizer = lambda x : [lmtzr.lemmatize(w) for w in x]
raw_df['tokens'] = raw_df['tokens'].apply(word_lematizer)
Feature Engineering
Bag of Words
We can extract Term Frequency to build a Bag of Words model or else use TFIDF statistic (which discounts words which are too common across documents). Though instead of calculating the TFIDF statistic, I chose to simply remove terms which are too common or too rare because removing redundant features all together seems preferrable to avoid over-fitting arising from high dimensionality.
Note - The earlier cleaning steps related to Stop Words removal and Non-Alphabetic tokens removal also addressed redundant dimensions.
sentence_creator = lambda x : [' '.join(x)][0]
raw_df['sentence_feature'] = raw_df['tokens'].apply(sentence_creator)
import sklearn.feature_extraction.text as sfText
vect = sfText.CountVectorizer()#(ngram_range = (1, 2))
vect.fit(raw_df['sentence_feature'])
X = vect.transform(raw_df['sentence_feature'])
tokenDataFrame = pd.DataFrame(X.A, columns = vect.get_feature_names())
tokens_redundant = token_sums[token_sums < 10].index
tokenDataFrame2 = tokenDataFrame.drop(tokens_redundant, axis = 1)
Sample Term Frequency dataset using two instances to demonstrate
| headline | better | black | catch | clerk | code | former | minority | mood | political | revival | roseanne | secret | shopper | store | sue | thorny | versace | worse |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| former versace store clerk sue secret black code minority shopper | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| roseanne revival catch thorny political mood better worse | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
The unigram BoW models ignore the word order and context. We can resort to n-grams to retain some context but it will lead to sparse high dimensional feature vectors. (have therefore commented the code chunk for n-grams)
Semantics
A better way to capture the context and latent relationships between different words including synonyms, antonyms, anologies etc is to use word2vec. The word2vec unsupervised models can learn context through vector representation of words called ‘word embeddings’ based on conditional probabilities of word occurrences around other words. Surprisingly, even with low dimensionality in hundreds, word2vec embeddings can learn really meaningful relationships. Once we have vectors for words, we can take the mean or sum of all words in a document to represent whole document as a single vector. There are also alternate doc2vec methods which directly learn vector representation for documents. I have chosen to average the word2vec embeddings because based on many posts on stack overflow community, they perform better than doc2vec when dealling with small to medium size corpus.
import gensim
w2v_size = 100
model = gensim.models.Word2Vec(raw_df['tokens'], size = w2v_size)
w2v = dict(zip(model.wv.index2word, model.wv.syn0))
# Word2Vec of Words
fetch_w2v = lambda x : [w2v[w] for w in x if w in w2v]
mean_w2v = lambda x : np.sum(x, axis=0)/len(x)
raw_df['fetch_w2v'] = raw_df['tokens'].apply(fetch_w2v)
raw_df['mean_w2v'] = raw_df['fetch_w2v'].apply(mean_w2v)
There is some more data wrangling then to transform the array of vectors to dataframe with each vector as a row. Corresponding code in Jupyter Notebook.
Sample 2-D representation of the word embeddings to show the model works:
# Principal Component Analysis to represent word embeddings in 2-D
from sklearn.decomposition import PCA
from matplotlib import pyplot
X = model[model.wv.vocab]
pca = PCA(n_components=2)
result = pca.fit_transform(X)
# create a scatter plot of the projection
pyplot.scatter(result[:, 0], result[:, 1])
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))
pyplot.rcParams['figure.figsize'] = [50, 100]
pyplot.show()
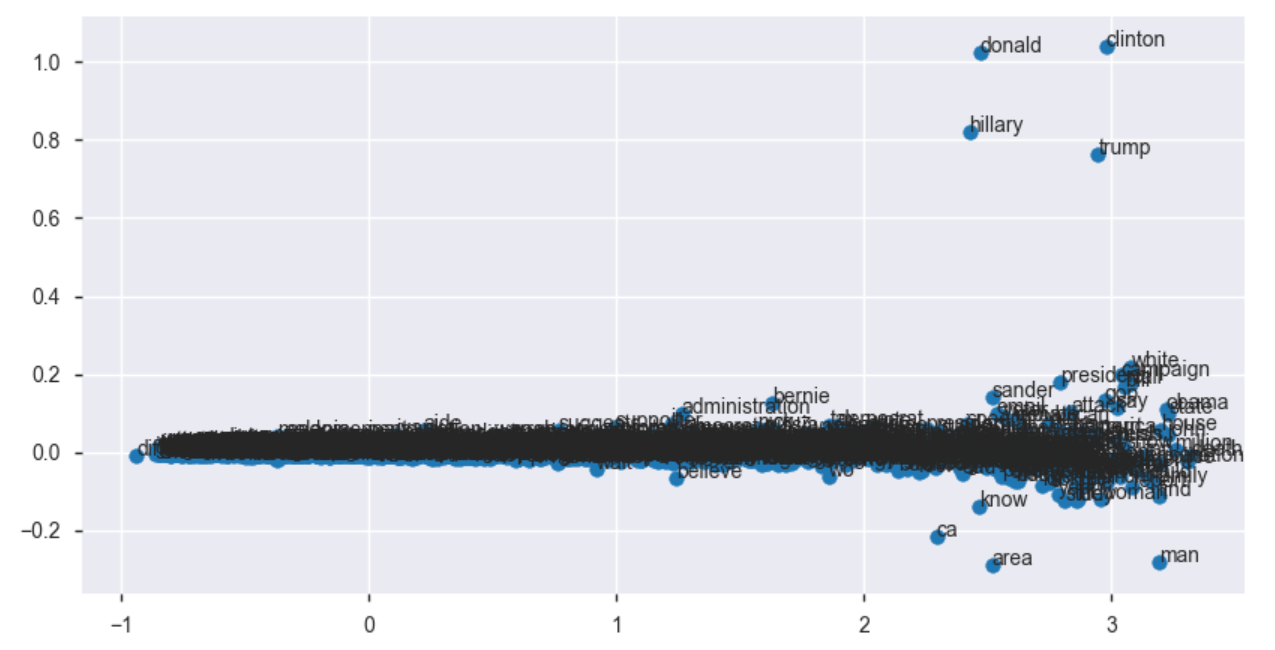
Behind the scenes magic of word2vec worked amazingly well as the model is grouping words by meaningful relationships (evident even in the 2-D representation of embeddings):
- Hillary-Clinton-Donald-Trump
- Obama-President-White-House-Campaign
- Area-Man
Model Training & Testing
Instead of using either/or we can combine the features from Bag of Words & word2vec to build our model. Subsequently, see which ones are more informative for this problem.
raw_df2 = pd.concat([w2v_DF, tokenDF_Final], axis=1)
Also, as a next step clearly state the training features & target variable.
redundant = ['is_sarcastic','article_link','headline_feature','sentence_feature','tokens','website_name']
features = list(set(raw_df2.columns) - set(redundant))
target_var = ['is_sarcastic']
Now, let’s build a Logistic Regression model (rather than a black-box model) as we are interested in the feature importance (i.e. weights).
Train/Test split: 80/20
from sklearn.model_selection import train_test_split, StratifiedKFold
train_data, test_data, train_target, test_target = train_test_split(raw_df2[features].as_matrix(), raw_df2[target_var], train_size = .8, random_state = 100)
5-Folds Cross Validated accuracy on Training Dataset: 83.7%
from sklearn import linear_model
clf = linear_model.LogisticRegressionCV(cv = 5, random_state=0, solver='lbfgs',multi_class='ovr',penalty='l2').fit(train_data, train_target.values.ravel())
clf.score(train_data, train_target.values.ravel())
Accuracy on Test Dataset: 78.4%
Note - Sarcasm Detection is a challenging problem due to nuances in meaning. Therefore, this accuracy is impressive (I wasn’t hoping to get ~80% accuracy when I set forth) but it is specifically for this news headlines dataset from theonion.com & huffingpost.com
from sklearn.metrics import accuracy_score
y_true = test_target.values.ravel()
y_pred = clf.predict(test_data)
accuracy_score(y_true, y_pred)
Confusion Matrix: (2539, 467, 688, 1648)
from sklearn.metrics import confusion_matrix
tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()
(tn, fp, fn, tp)
Feature Importance
The magnitude of the coefficients in logistic regression can be loosely interpreted as feature importance (or use pow(math.e, w) to be more accurate). Other ways for finding feature importance or parameter influence include using p-values, drop column feature importance or permutation feature importance
weights = clf.coef_
feature_weights = weights[0]
feature_abs_weights = np.abs(weights[0])
feature_names = np.array(raw_df2[features].columns)
feature_importance = pd.DataFrame({'Features':feature_names, 'Weights':feature_weights, 'Weights Absolute':feature_abs_weights}).sort_values(by='Weights Absolute', ascending=False).reset_index(drop = True)
feature_importance.head(12)
| Features | Weights | Weights Absolute | |
|---|---|---|---|
| 0 | area | 2.860869 | 2.860869 |
| 1 | nation | 2.499772 | 2.499772 |
| 2 | introduces | 2.109260 | 2.109260 |
| 3 | shit | 2.069392 | 2.069392 |
| 4 | local | 1.957934 | 1.957934 |
| 5 | self | 1.894267 | 1.894267 |
| 6 | fucking | 1.885271 | 1.885271 |
| 7 | report | 1.877206 | 1.877206 |
| 8 | study | 1.812988 | 1.812988 |
| 9 | clearly | 1.657876 | 1.657876 |
| 10 | man | 1.657209 | 1.657209 |
| 11 | announces | 1.611359 | 1.611359 |
We discussed in the beginning why the words - ‘area’, ‘man’ & ‘clearly’ show up as top features to identify sarcasm.
Other top features like ‘introduces’, ‘report’, ‘study’, ‘announces’, ‘unveils’ has to do with sarcastic emphasis around false claims.
‘introduces’
| article_link | headline_feature | is_sarcastic |
|---|---|---|
| https://www.theonion.com/3m-introduces-new-line-of-protective-foam-eye-plugs-1822590036 | 3m introduces new line of protective foam eye plugs | 1 |
| https://local.theonion.com/burger-king-introduces-new-thing-to-throw-in-front-of-k-1819573136 | burger king introduces new thing to throw in front of kids after another hellish day at work | 1 |
‘study’
| article_link | headline_feature | is_sarcastic |
|---|---|---|
| https://www.theonion.com/study-more-couples-delaying-divorce-until-kids-old-eno-1819576618 | study: more couples delaying divorce until kids old enough to remember every painful detail | 1 |
| https://www.theonion.com/study-universe-actually-shrunk-by-about-19-inches-last-1819589814 | study: universe actually shrunk by about 19 inches last year | 1 |
whereas ‘fucking’ is used for sarcastic exaggeration to invoke humor
| article_link | headline_feature | is_sarcastic |
|---|---|---|
| https://www.theonion.com/frontier-airlines-tells-customers-to-just-fucking-deal-1819580035 | frontier airlines tells customers to just fucking deal with it | 1 |
| https://www.theonion.com/girls-scouts-announces-they-ll-never-ever-let-gross-fuc-1825752568 | girls scouts announces they’ll never ever let gross fucking boys in | 1 |
and ‘self’ is sarcastically calling out bad judgement/vanity etc
| article_link | headline_feature | is_sarcastic |
|---|---|---|
| https://local.theonion.com/just-take-it-slow-and-you-ll-be-fine-drunk-driver-a-1820399426 | ‘just take it slow, and you’ll be fine,’ drunk driver assures self while speeding away in stolen police car | 1 |
| https://www.theonion.com/narcissist-mentally-undresses-self-1819567215 | narcissist mentally undresses self | 1 |
Also, note that the latent features we learnt using word2vec appeared quite low in importance.
feature_importance[feature_importance.Features.isin(w2v_col_names)]
| Features | Weights | Weights Absolute | |
|---|---|---|---|
| 700 | c42 | 0.588654 | 0.588654 |
| 1062 | c94 | 0.471734 | 0.471734 |
| 1152 | c78 | 0.451407 | 0.451407 |
| 1170 | c85 | -0.447847 | 0.447847 |
| 1310 | c61 | 0.412665 | 0.412665 |
It probably has to do with the nature of articles in theonion.com and also, the relatively small size of corpus that the Bag of Words features turned out to be more informative for our model. But in other settings, when the size of corpus increases, the large vocabulary leads to sparse high dimensional feature vectors and in those problems the low dimensional dense feature vectors from word2vec will likely serve us better.
Appendix
BOW & TF-IDF
- Limitations - sparse representations, large vector size, don’t capture semantics
Word2Vec
- Take a fake problem (CBOW or Skipgrams)
- Solve it using neural network
- You get word embeddings as a side effect
- Two methods
- 1. CBOW : Continuous Bag of Words - Given context words predict the target word
- 2. Skipgrams - Given the target predict context words
GloVe : Global Vectors for Word Representation
- Similar to Word2Vec
BERT : Bidirectional Encoder Representations from Transformers
- Based on transformer architecture
Leave a Comment