Introduction
We’ll not be killing so much time on Netflix and YouTube, if our home pages weren’t personalized through a sophisticated Recommender System on the backend which keeps you hooked by surfacing apt content based on your genre preferences, context, viewing history, overall popularity, recent releases and currently trending etc.
Beyond being an interesting ML problem, Recommender Systems also require immense engineering scale as it often involves building a massive similarity matrix (for items and/or users) apart from a rich feature store for items and users.
In this post, I’ve attempted to build an RS through several popular approaches (content based, collaborative filtering, matrix factorization) and new bleeding edge approaches (deep learining). And also, compared them on key evaluation metrics while discussing challenges of scaling, cold-start, stoplist, filter bubbles, outliers, trust and ethics.
The full code is on github.
Sample User
Throughout our analysis, I’ll also go back and check the top-10 recommendations for userId = 410 (which has somewhat similar taste preferences as me) to do a quick eye test of recommendations quality (& plus its fun). This may additionally help us understand how the recommender is working under the hood and augment quantitatve evluation metrics like Hit Rate & RMSE.
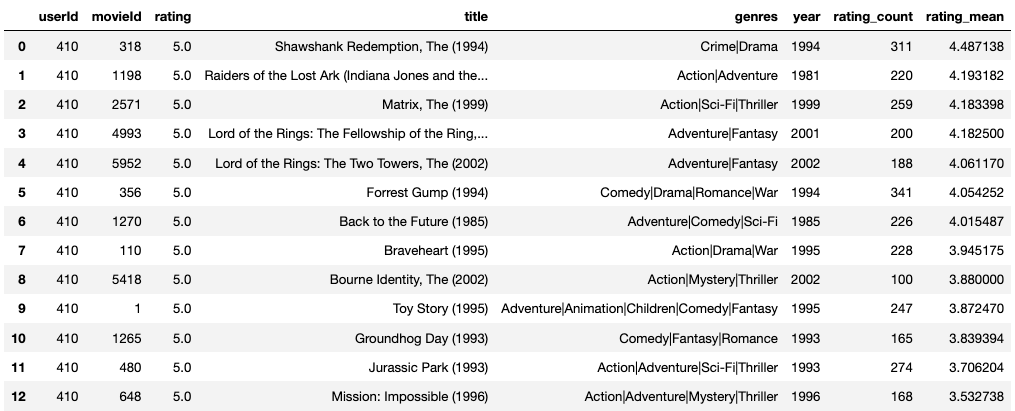
Movies Rated 5-Star by userId = 410

user_id = 410
user_data = ratings_data[['userId','movieId','rating']][ratings_data['userId'] == user_id]
user_data = pd.merge(user_data, rating_count_per_movie, how='inner', left_on = ['movieId'], right_on = ['movieId'], right_index = False)
user_data.sort_values(by=['rating','rating_mean'], ascending=[False,False]).reset_index(drop=True).head(10)
About MovieLens Data
I’ll be experimenting with the MovieLens-Small data set which consists of 100,000 ratings and 3,600 tag applications applied to 9,000 movies by 600 users.
Sample Data Exhibit
ratings_data = pd.read_csv('/ml-latest-small/ratings.csv')
movies_data = pd.read_csv('/ml-latest-small/movies.csv')
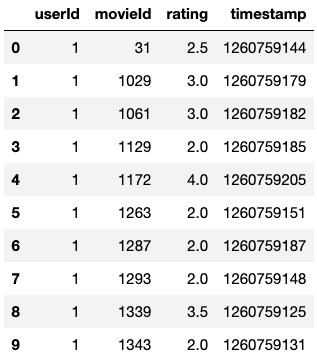
User Ratings for Movies
ratings_data.head(10)
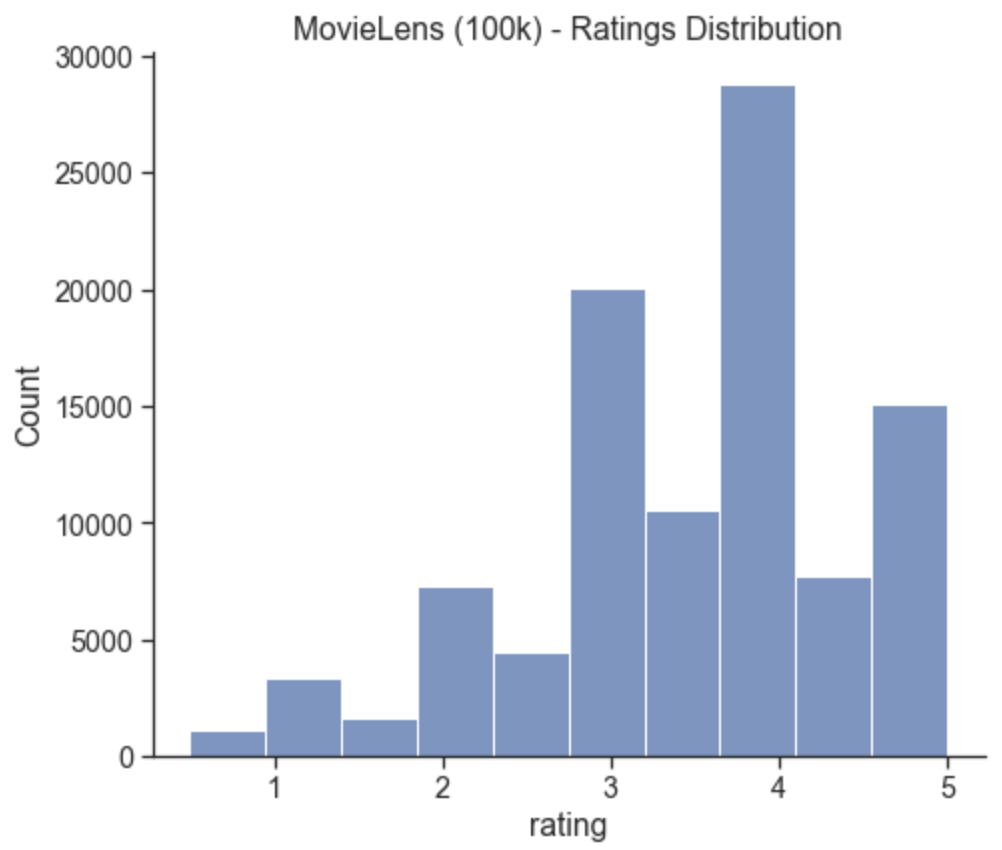
sns.displot(ratings_data['rating'], bins=10, height=6, aspect=1.2).set(title='MovieLens (100k) - Ratings Distribution')
Movie Attributes
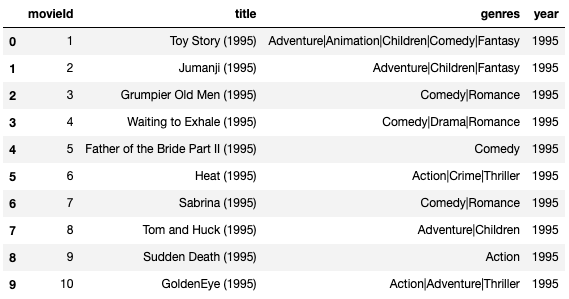
movies_data.head(10)
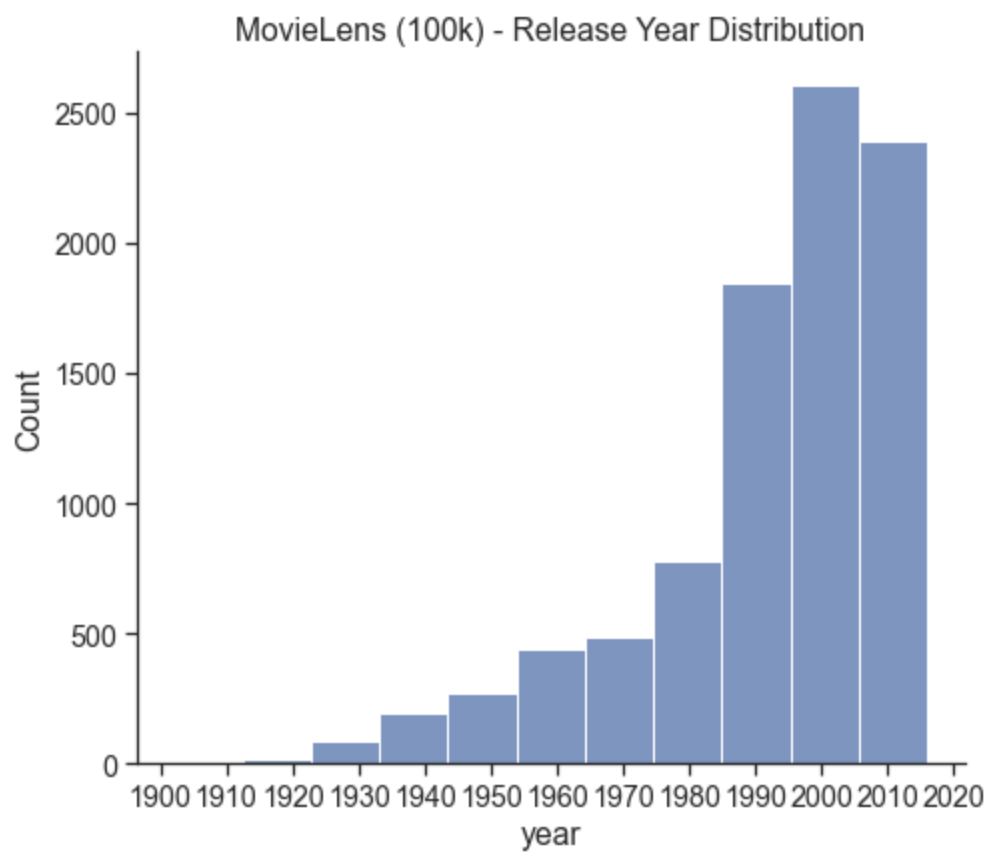
sns.displot(movies_data['year'][movies_data['year'] != 0], bins=11, height=6, aspect=1.2).set(title='MovieLens (100k) - Release Year Distribution')
plt.xticks(np.arange(1900,2030,10))
Appendix
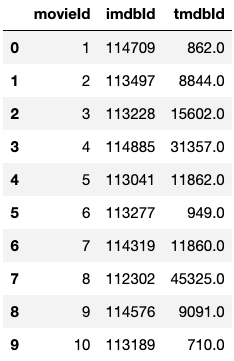
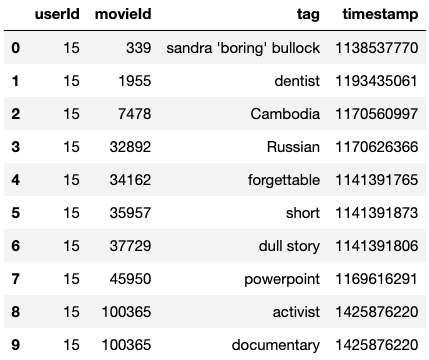
There are additional datasets on the tags which are user-generated metadata about movies and the IMDb links for the movie titles (to potentially scrape data about cast, production and director).
links_data = pd.read_csv('/ml-latest-small/links.csv')
tags_data = pd.read_csv('/ml-latest-small/tags.csv')
Links Data
Tags Data
Leave a Comment